データ研磨スキル
[導入編]
2021/02/20
到達目標
初級編
- データの読込から結合、集計などのデータ研磨を行い、データの出力までを自由にできるようになる
中級編
- 複数ファイルに対して効率的な処理を実行できる
- 与えられた指標算出ロジックを実装できる
- 基本的なデータの可視化を実行できる

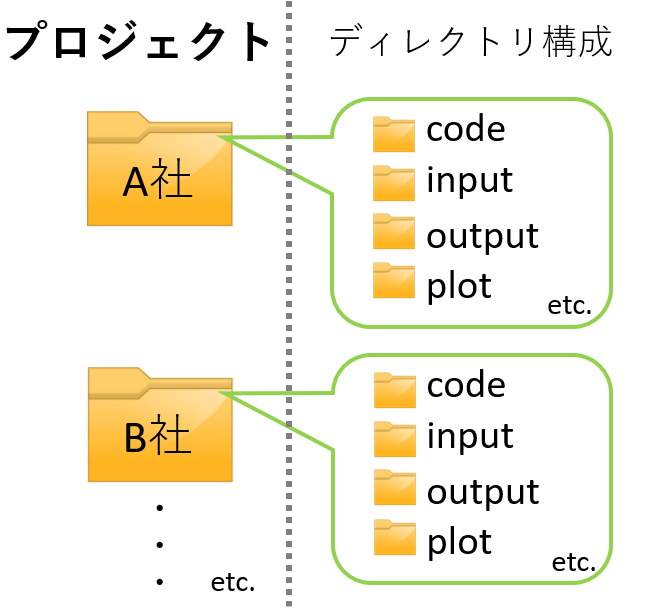
プロジェクトとは
- A社のデータ研磨、B社のデータ研磨、というように、案件の最も大きなくくりのことをプロジェクトと呼びます
- プロジェクトごとにフォルダを1つ作成します
- フォルダ下は統一されたディレクトリ構成(後述)を持つことが望ましいです
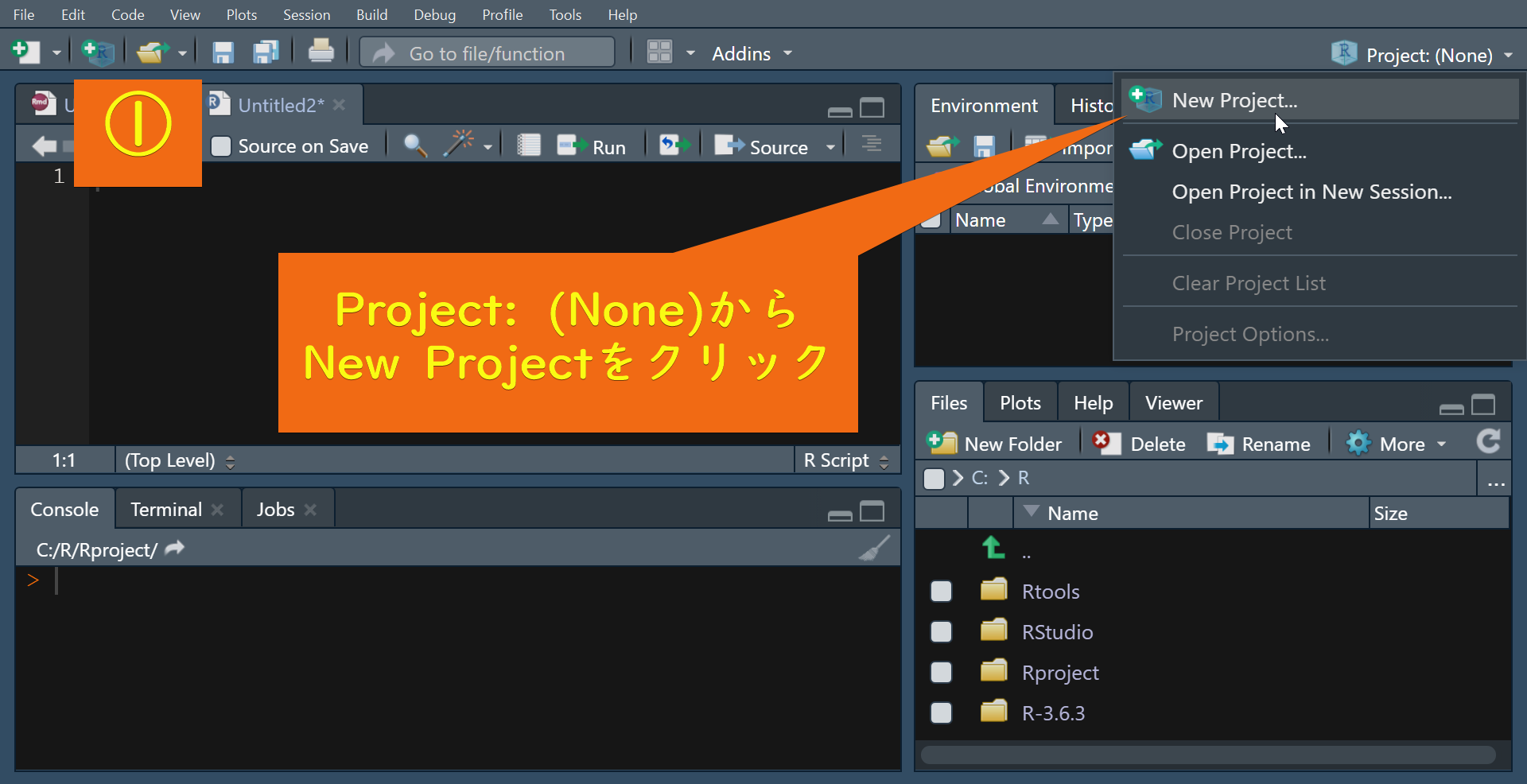
R projectの作成
①から④の手順に従ってR Projectを作成します。
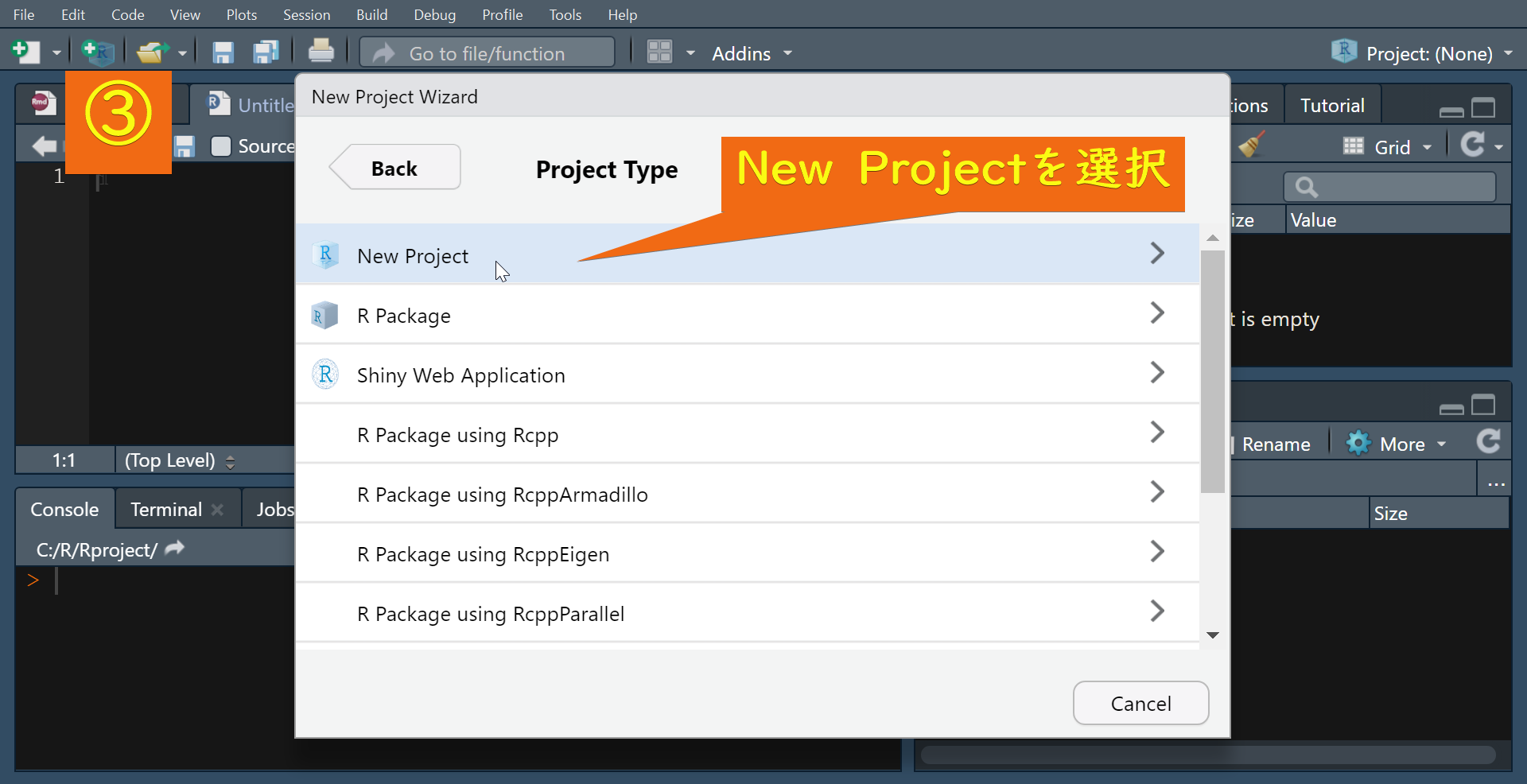
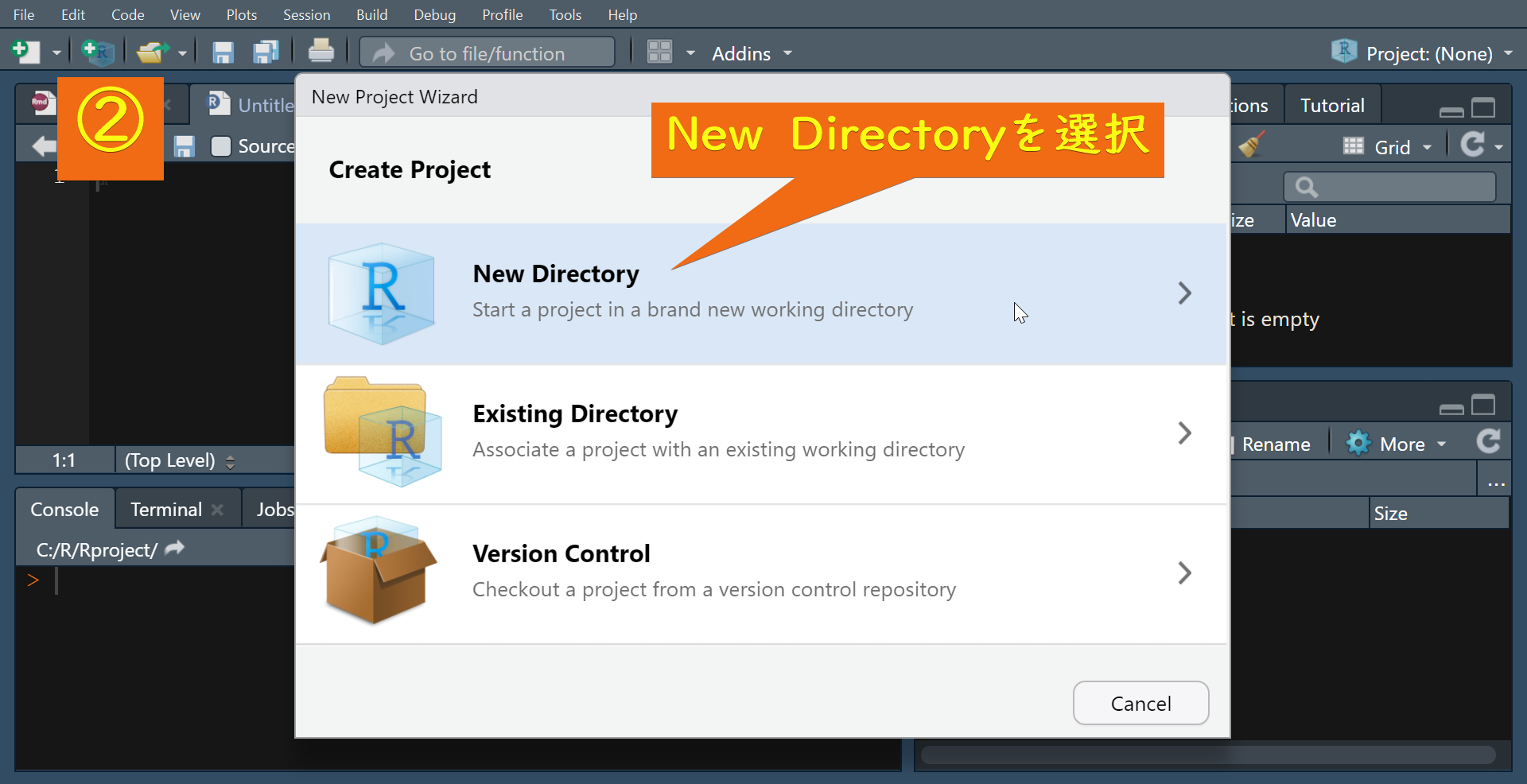
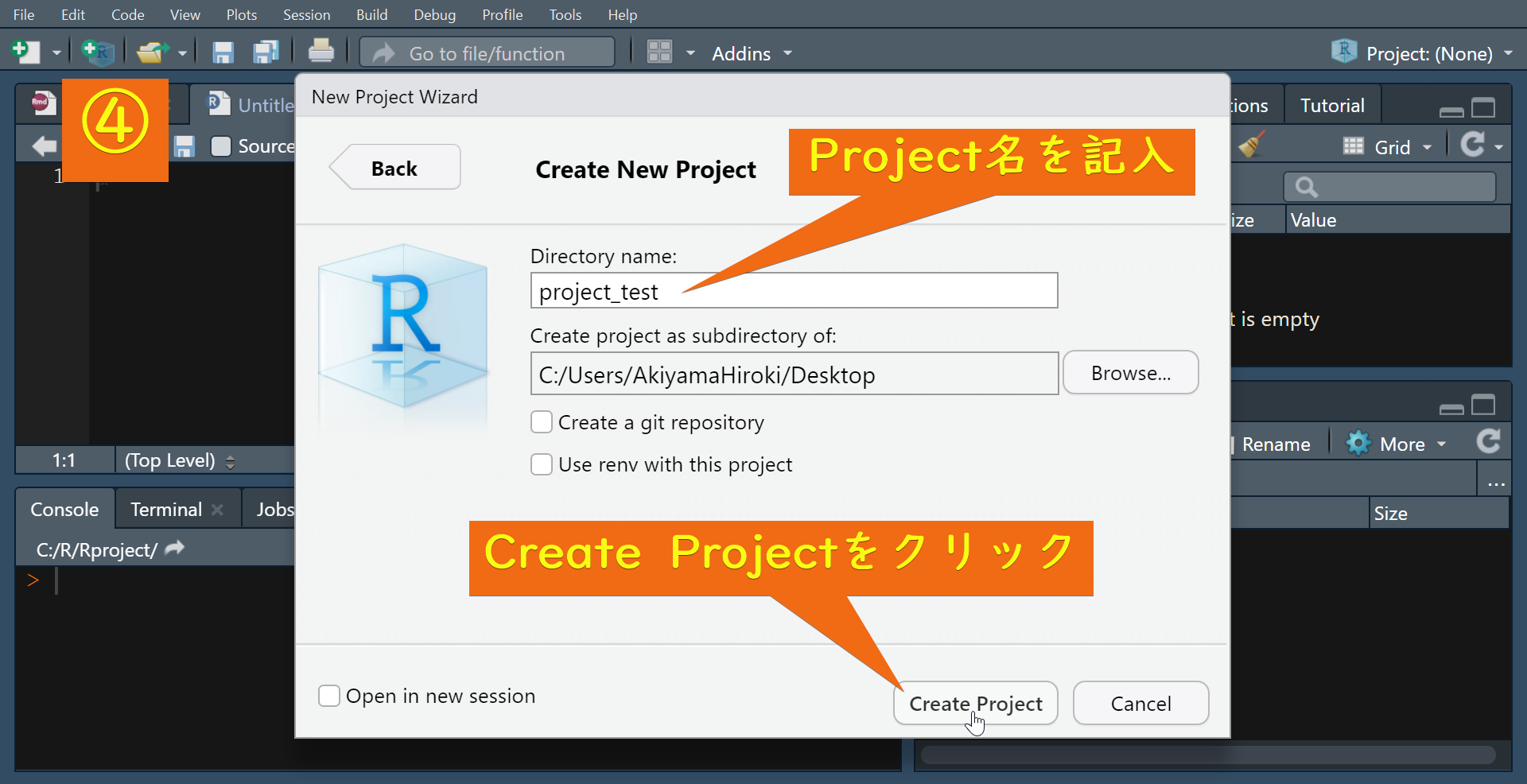
R projectが作成されると次のような画面が開きます。
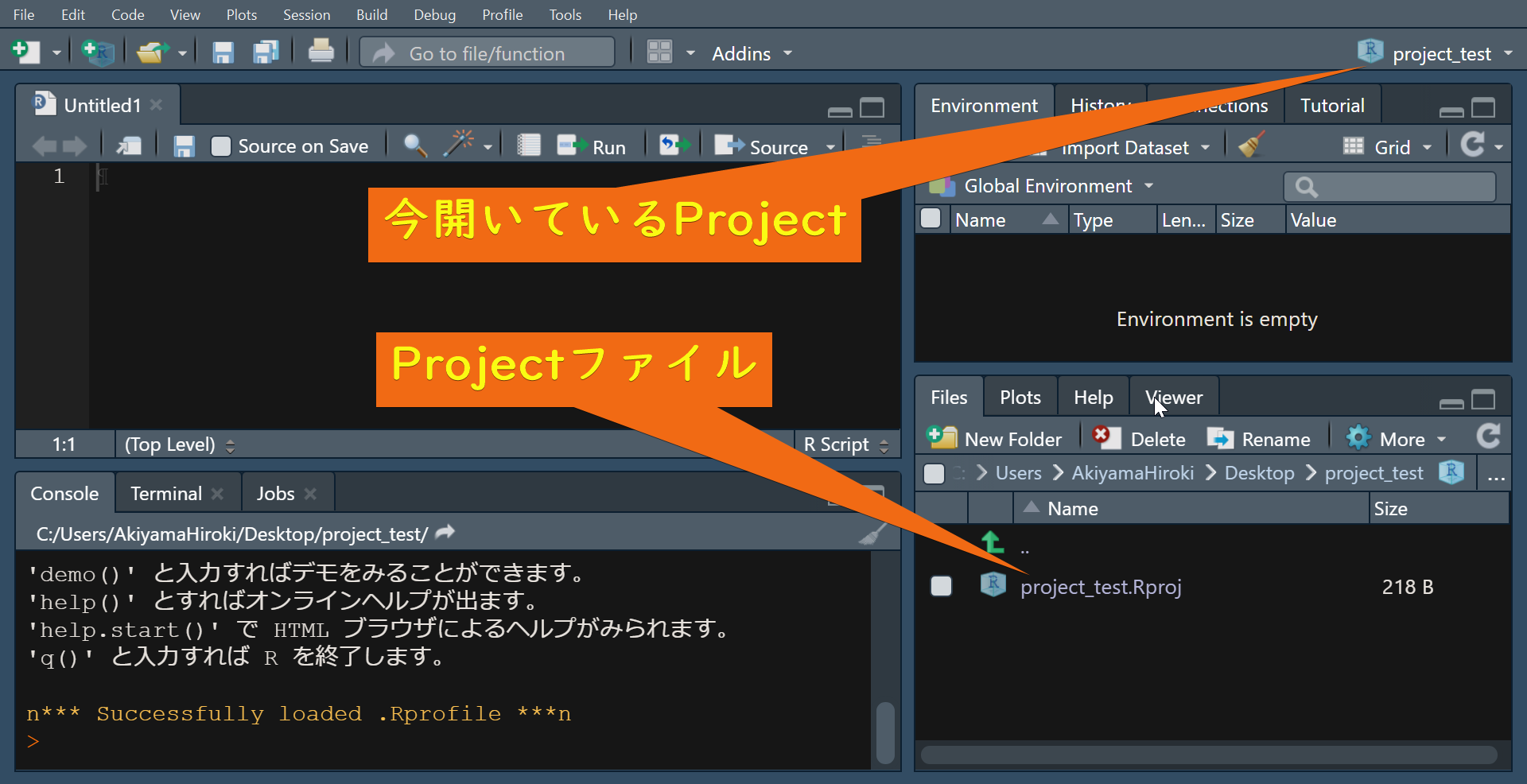
ExplorerからR projectを起動することもできます。
ディレクトリ構成とは
- 文字通り、ディレクトリの構成のことです
- ディレクトリ構成を事前に定義しておくと、個人にとっても複数人にとっても有益な事がたくさんあります
- たとえば、demo_dirというプロジェクトのディレクトリ構成が右下図のようになっているとします
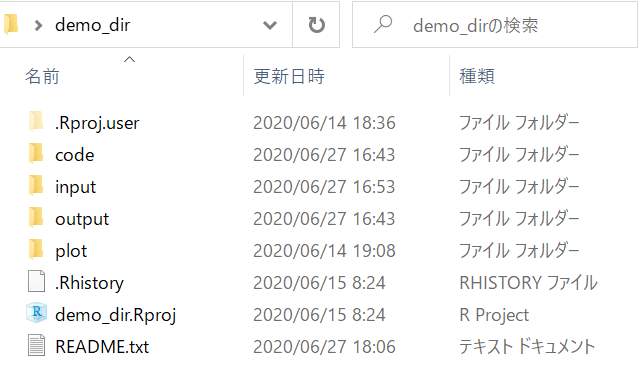
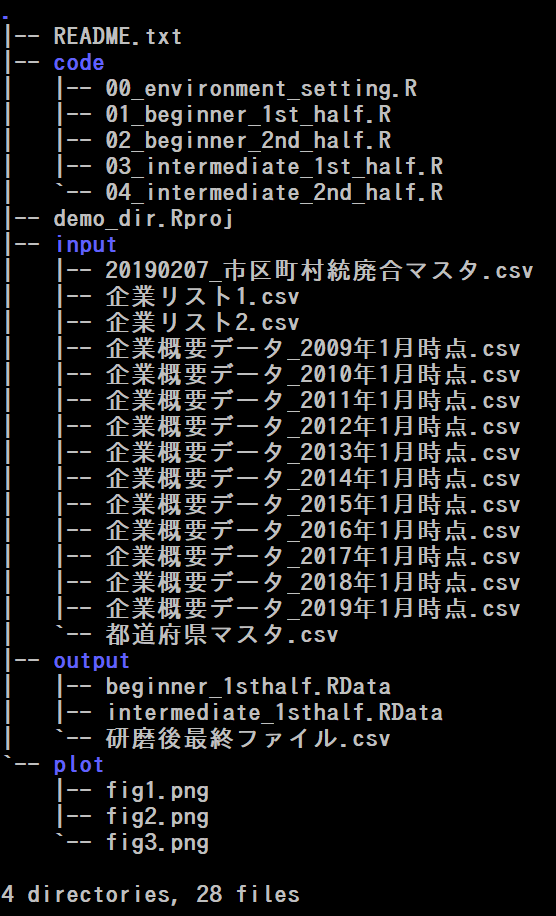
demo_dirのディレクトリ構成詳細
青字はフォルダです
| フォルダ | 中身 |
|---|---|
| . | ルートディレクトリ(demo_dir) |
| code | .Rファイルなどの研磨スクリプト |
| input | 生データやマスタデータ |
| output | 中間ファイルや研磨後データ |
| plot | データの可視化をしたプロット |
| ファイル | 内容 |
|---|---|
| README.txt | 最初に読んでほしい文書。構成や備忘録などを記述 |
| demo_dir.Rproj | プロジェクトファイル |
ディレクトリ構成の事例
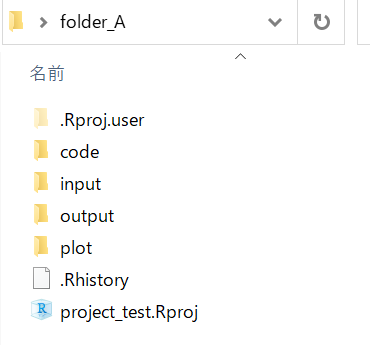
folder_A
folder_B
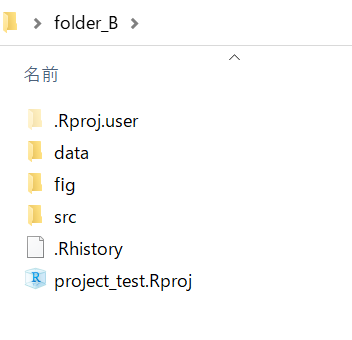
両フォルダとも中身は同じですがフォルダ名が少し異なります。 フォルダ名は統一されている方が共有がしやすいです。 本資料ではfolder_Aのような構成で進めます。
悩み事例の視覚的説明
- 先ほどの事例を視覚的に説明します
- 下図のように、Project_Aというプロジェクトフォルダが鈴木さんのWindowsのDesktop上にあるとします
- このとき、読み込みたいデータdata.csvまでの絶対pathは以下のようになります
C:/Users/Suzuki/Desktop/Project_A/input/data.csv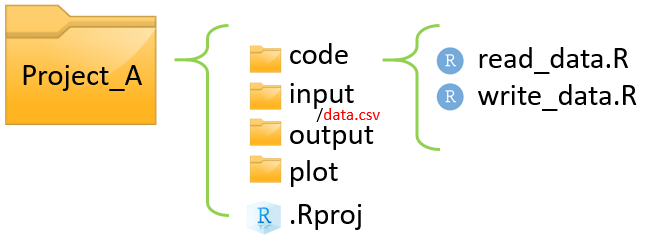
異なるOS/個人間によるpath相違の解消
- Windowsユーザーの鈴木さんが作成したProject_Aを、Macユーザーの田中さんが受け取りました。
- 田中さんはProject_AをDocumentsに置きました
- dataまでの絶対pathは以下のように変更が必要です
変更前 C:/Users/Suzuki/Desktop/Project_A/input/data.csv
変更後 /Users/Tanaka/Documents/Project_A/input/data.csv
hereを使ったpath
- 前頁で絶対pathの変更を示しましたが、Project_A以下に関しては変える必要がありませんでした
- つまり、Project_Aがルートディレクトリになってくれるとpathの変更が必要なくなるということです
- これを実現してくれるのがhereです
- プロジェクトが起点になるため、プロジェクトフォルダを共有した際、pathを書き換える必要がなくなります
- 異なるOS間でのpathの齟齬も解消されます
- 以上の理由から、本資料ではhereを使用しています
here("input/data.csv")"C:/Users/ユーザー名/Desktop/Project_A/input/data.csv"
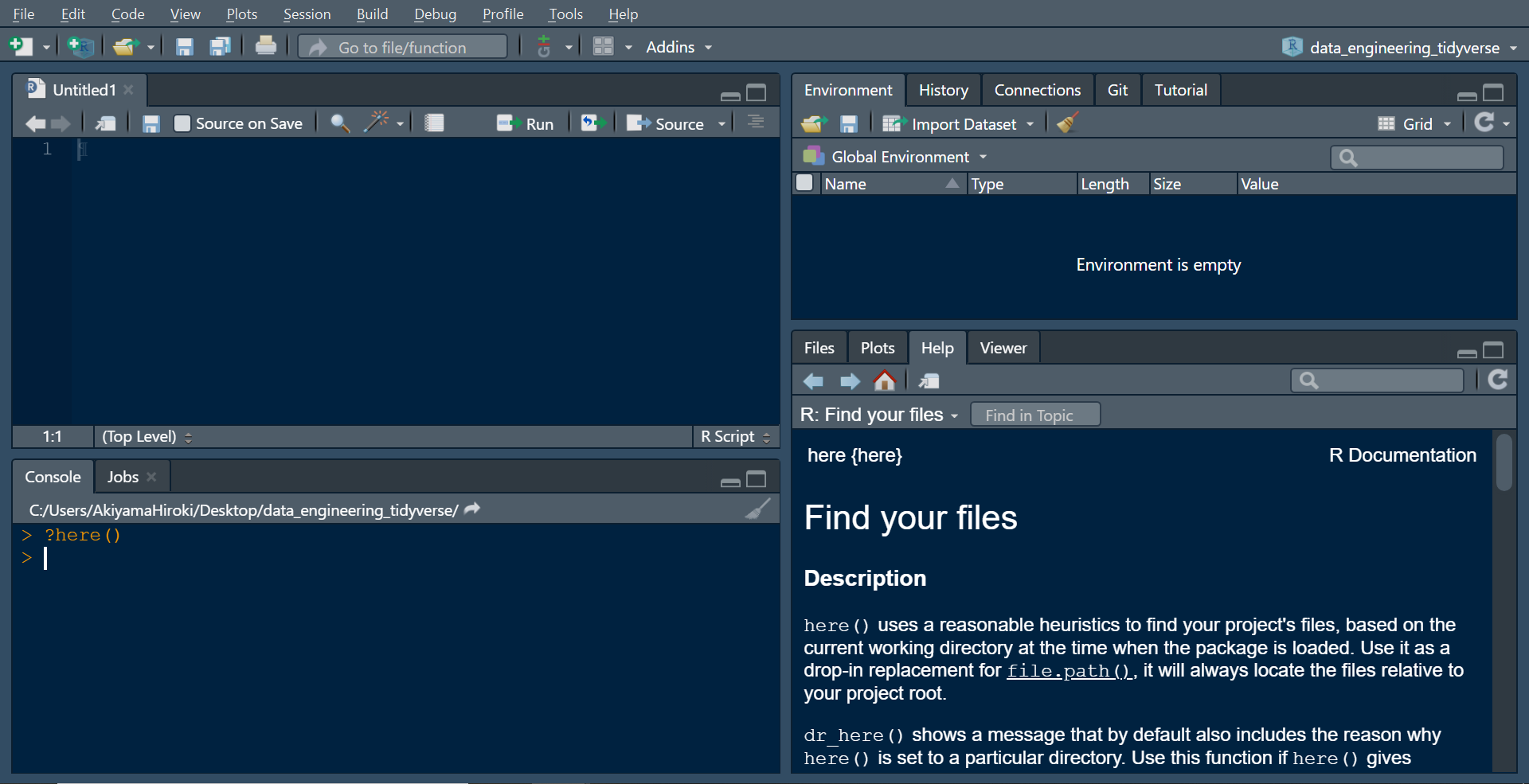
“?関数名”でhelp
- helpファイルを開くには、helpを見たい関数の頭に?マークを付けて実行します
- 関数の括弧はあってもなくても大丈夫です
- help(関数名)としても同様です
- Rstudioでは右下のHelp paneでhelpファイルが見れます
?here
?here()
help(here)